

This how to guide explains does Jigit works in relation to the scalability and performance considerations
Basic Functionality
The Jigit plugin indexes commits and pull/merge requests from GitHub/GitLab using their REST API and stores them in the database. A REST API call to GitHub/GitLab is made for each commit.
Diagrams
Indexing Job
The following diagram illustrates how the indexing job runs at a high level for each repository:

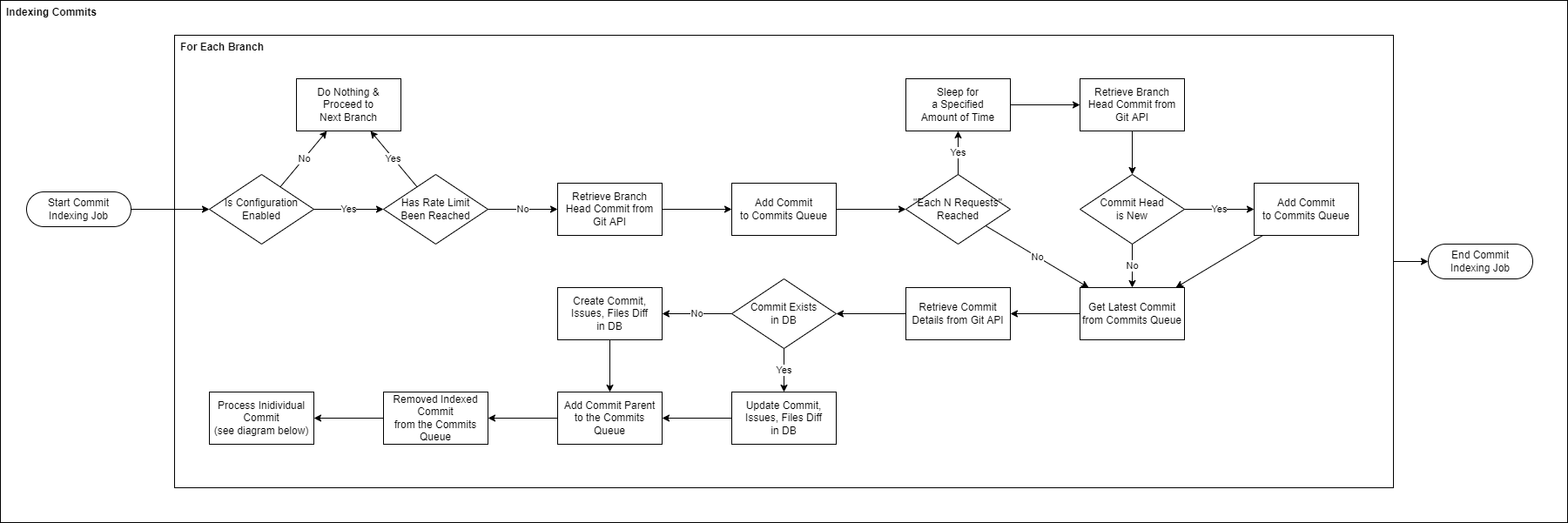
Indexing Commits
The following diagram illustrates how indexing commits within a single repository works in detail:
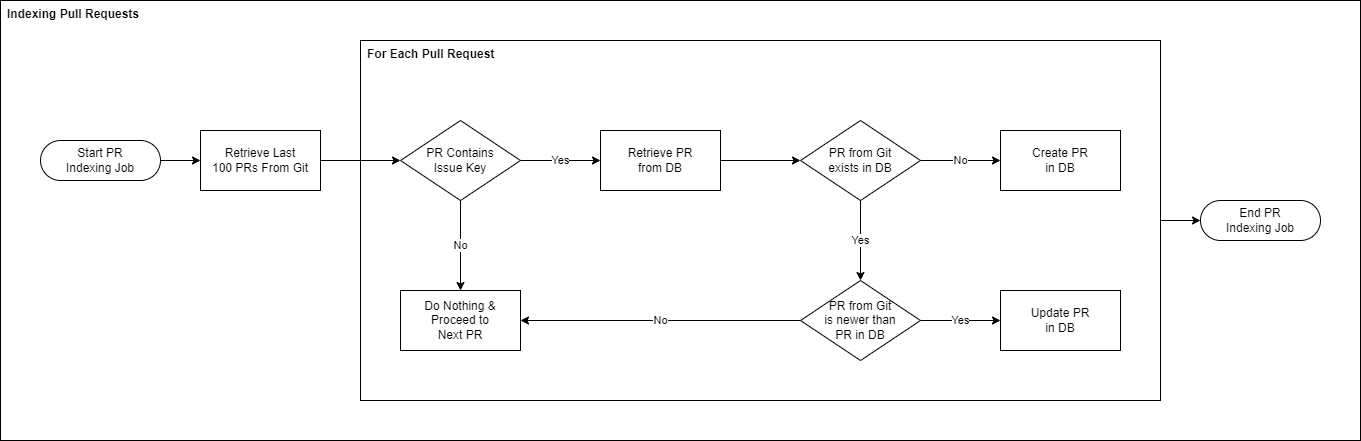
Indexing Pull Requests
The following diagram illustrates how indexing pull requests within a single repository works in detail:
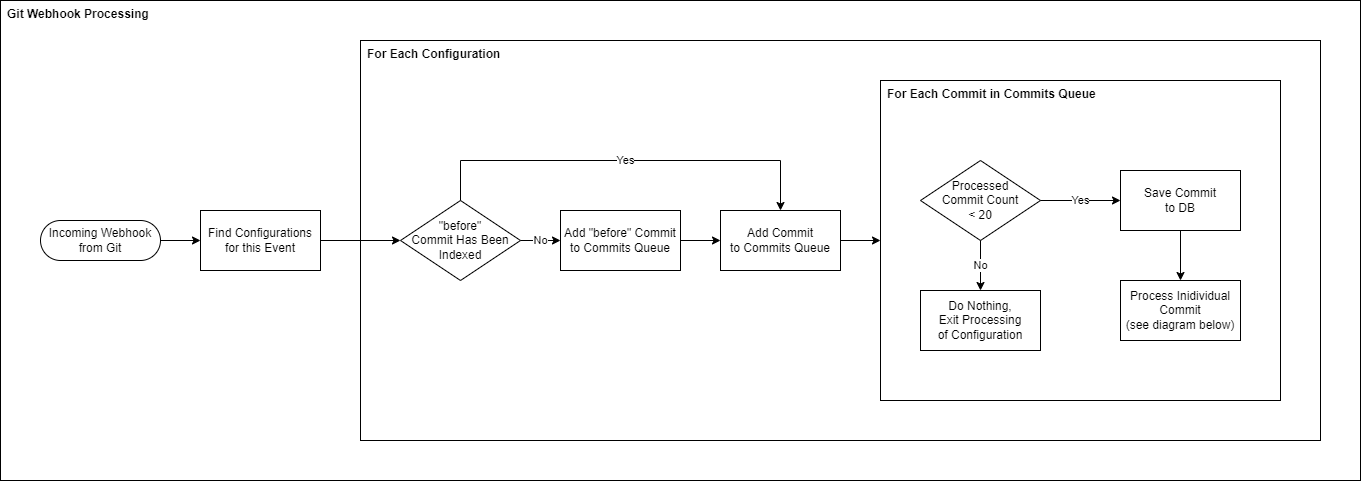
Git Webhook Event Processing Diagram
The following diagram illustrates how incoming webhook events from Git are processed.
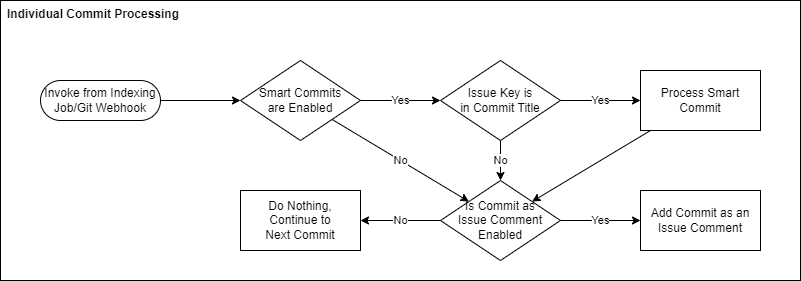
Individual Commit Processing Diagram
The following diagram illustrates how individual commits are processed at the end of the “Indexing Commits” and “Git Webhook Event Processing” diagrams above.
Indexing Types
Repository & Group Indexing
|
|
Repository Indexing |
Group Indexing |
|---|---|---|
|
What it does |
Indexes commits from a single repository |
Indexes commits from multiple repositories in parallel. |
|
Runs against |
Configured GitHub/GitLab repository. |
All repositories matching the |
Initial & Ongoing Indexing
|
|
Initial Indexing |
Ongoing Indexing |
|---|---|---|
|
What it does |
Indexes all commits from all configured repositories up to the first commit in the repository or up to a commit older than the value set for |
Indexes all commits since the last indexing job |
|
When does it run |
Once-off after a new configuration is created |
On an on-going basis every few minutes |
|
How is it run |
A job is scheduled to run as soon as the configuration is saved. This job triggers the indexing process. |
A job is scheduled to run every few minutes. This job triggers the indexing process. |
Indexing Workflow
The indexing process consists of the following steps:
-
Retrieve the head commit for the branch
-
Add it to the
head of commitsqueue -
Read the commit hash from the
head of commitsqueue-
If it’s not indexed → retrieve commit info from GitHub/GitLab and save it to the database
-
If it’s already indexed, proceed to the next commit in the
head of commitsqueue
-
-
Read the parent commit from the commit info and append it to the commits queue
-
Check if the rate limit has been reached
-
If it has not been reached, continue processing commits (step 3)
-
Wait for a specified time (
Sleepinterval) and start the whole process from scratch (step 1)
-
The workflow is performed for suitable branches iteratively - a branch is indexed only after the indexing of the previous one has been completed. The order of branches depends on how GitHub/GitLab returns them.
Performance & Scalability
Requests Throttling/Rate Limiting
While Jigit is highly scalable and can support large amounts of repositories and commits, GitHub & GitLab APIs have a rate-limiting restriction, which allows a maximum number of REST API requests per hour. Any additional requests sent during that hour to their REST APIs will be rejected. Jigit handles such cases and stops indexing until requests are no longer rejected. Usually in this case, the user can see the following message in the Jigit administration next to the configuration:
Repository request limit exceeded. Next indexing starts after ...
Requests throttling might happen if:
-
During initial indexing due to the large amount of data that needs to be indexed
-
Jigit configuration is for a Group and the Group has many repositories - repositories are indexed simultaneously.
-
Jigit configuration indexes all branches in a repository/repositories.
-
each … requestssetting is high andsleepinterval is small.
Best Practices to Solve Requests Throttling Issues
-
If you have a large number of commits, do not index them all at once initially. Make sure you set the
Commit indexing windowto some small period (5 days, for example) and then increase it gradually every few days until you can remove it completely (the default value is 30 days). -
Make sure you have separate configuration rules for groups of repositories, especially if they have a known pattern. For example, if you have repos with front-end apps that are named
frontend-<name-of-app>, you can create a configuration rule using the maskfrontend-.*. -
Create separate users/tokens and rules for very frequently and heavily used repositories. This way they will have a separate indexation job.
-
If you cannot use multiple users/tokens, you can create multiple configurations (use
Repository patternfor the groups). You can then enable one of them and disable all others. Once the indexing of that one configuration is done, you can disable it and enable the next one, repeating the same process when it finishes. Once the initial indexing finishes for all configurations, you can enable them all so that ongoing indexing can be done for all of them. -
Reduce the
each … requestssetting and increase thesleepinterval. -
Don’t index all the branches but only the required ones (
selected branchesmode).
Technical Details
Job Scheduler
-
The plugin schedules one indexing job per cluster.
-
The indexing job is scheduled to run by default every 2 minutes. This configuration can be changed via the Global settings or via the environment/Java property variable
moveworkforward.jigit.index.interval. -
Each job is scheduled by the previous one only after it finishes.
Indexing Details
-
Indexing runs in 2 separate threads.
-
Each Git repository represents an indexing task. This means that only two tasks can run simultaneously. Group configuration creates several tasks equal to the involved repositories.
-
Branches in each repository are processed sequentially.
-
The head commit for every branch is checked when indexing starts or after a sleep period of the current indexing job.
-
The SHA-1 of every commit is added to the commit queue to process. The queue is persisted in the database which means that it survives restarts.
-
The commit SHA-1 is removed from the queue only when commit data is fetched from Git.
Javafinal Collection<String> nextCommits = persistStrategyFactory. getStrategy(repoName, commitAdapter, counter > skipCount, repoInfo.getIndexDaysLimit()). persist(repoInfo.getRepoGroup(), repoName, branch, commitAdapter, issueKeys, commitDiffs); commitQueue.addAll(nextCommits); commitQueue.remove(commitSha1); -
Indexation of pull requests is done only after all commits have been processed.
Indexing Example
Assume we have a group of 300 repositories and we create a configuration for that group. The approximate indexing calculation for it is as follows:
-
3 requests to get all repositories for branch indexing (100 repositories/request)
-
300 requests to get branches for these repositories (1 request/repository)
-
3 requests to get all repositories for pull-request indexing (100 repositories/request)
-
300 requests to get pull requests for these repositories (1 request/repository)
-
600 requests to get the commit difference for all branches (assuming we have on average 2 branches with issue keys or linked to issues by the user, i.e. 2 * 300 requests)
This totals 1206 requests to index the branches and pull requests.
With 2 minutes of indexing timeout, we reach the 5K limit in 4-5 indexing jobs, which is about 8-10 minutes. To solve the throttling issue we need to increase both intervals to 15 minutes.
Formula
(N/100 + 1 + N + N*M)(3600/K) + (N/100 + 1 + N)(3600/L) = R
N - number of repositories
M - the average number of branches to get commit details(linked or contains issue key in the name)
K - branch indexing timeout
L - commit/pull-requests indexing timeout
R - requests limit(5000)
This means that if we have the same intervals (K = L), then:
(2(N/100 + 1 + N) + N*M)(3600/K) = R
meaning:
K = (2(N/100 + 1 + N) + N*M)(3600/R)
Where K is a minimum timeout in seconds for both indexing jobs to avoid throttling.
Updated: